Rescuing your data from Goodreads
In the previous post I mentioned that I wrote a script to extract the "started reading" dates from GR.
Here it is, in case you need it. All the usual disclaimers about no warranty and running a stranger's code from the internet apply. 😄
It's a C# script written in LINQPad. The easiest way to run it is to just download the file, read the instructions, and run it. If you don't wanna, or are on a platform where Linqpad is unavailable, you can just put the C# code into a text file. (See below.)
What does it do
- Reads a list of GR book IDs you want to scrape dates from
- Does a slow crawl of GR, scrapes the dates
- Stores them into a LiteDB.
In case you don't know it, LiteDB is a flat-file document-based DB. So basically, like SQLite, except easier to use for object storage.
You can read the results trivially either via C#, or the LiteDB.Studio.
Goodreads has changed its UI recently, and might do it again. Since this script is based on HTML scraping, it might break easily. Worked fine for me, might break before you get around to trying it.
Also, the new UI seems to be hiding some things behind JS loaders, which makes it harder to extract, though I'm sure that's just a coincidence.
However, I've found out that when I open GR in MS Edge, I consistently get the older layout. So I set this script's headers to mimic Edge's requests.
⚠ BE ADVISED: since you can only see your data on a book's page if you're logged in, you will need to copy your cookies into the script.
It's written in .NET 7, with the "enable C# preview features" setting enabled, because of the improved string interpolation options.
Results
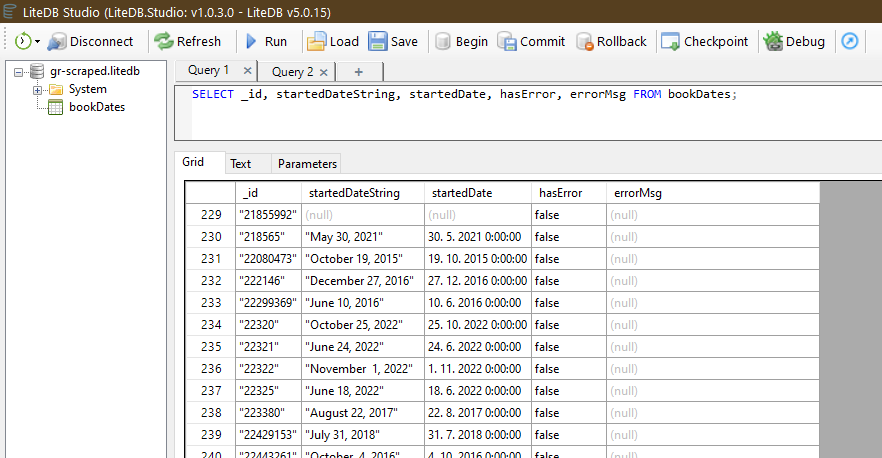
How-to
1. Book IDs
The script expects a list of Goodreads' Book IDs. It's easiest to get it by exporting CSV data from Goodreads via their export function, then filtering the Book IDs for books on the "read" exclusive shelf.
Save them into a file, one per line.
2. Cookies
- Open your browser's dev tools
- Log into GR
- Look into the Network tab
- Find a request that has the
Cookiekey amongst its headers, copy its value - Paste it into the requestg, line 28.
3. Paths
Set the path for the output DB on line 3, and for the input Book ID list on line 6.
4. Run
Hit run. It will take some time - there are randomized delays between requests. I don't know if GR will auto-block you if you do too many requests, but I don't wanna find out.
Issues?
If the thing broke, the fix may or may not be easy. The best case scenario is that you'll only need to inspect the HTML, find the "Started reading" part and modify the regex on line 31.
Running without LINQPad
You can get the code either form the file download at the top, or from the listing below. You'll also need to add a reference to these nugets:
FlurlFlurl.HttpLiteDB
The code is here:
async Task Main()
{
using var db = new LiteDatabase(@"gr-scraped.litedb");
var dates = db.GetCollection<GrBookDateData>("bookDates");
foreach (string bookId in File.ReadAllLines(@"RELEVANT_ID_FILES.csv"))
{
var url = "https://www.goodreads.com/book/show/" + bookId;
if (dates.FindById(bookId) != null)
continue;
var response = await url
.WithHeader("Cache-Control", "max-age=0")
.WithHeader("sec-ch-ua", "\"Microsoft Edge\";v=\"107\", \"Chromium\";v=\"107\", \"Not = A ? Brand\";v=\"24\"")
.WithHeader("sec-ch-ua-mobile", "?0")
.WithHeader("sec-ch-ua-platform", "\"Windows\"")
.WithHeader("Upgrade-Insecure-Requests", "1")
.WithHeader("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36 Edg/107.0.1418.56")
.WithHeader("Accept", "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3; q = 0.9")
.WithHeader("Sec-Fetch-Site", "none")
.WithHeader("Sec-Fetch-Mode", "navigate")
.WithHeader("Sec-Fetch-User", "?1")
.WithHeader("Sec-Fetch-Dest", "document")
.WithHeader("Accept-Encoding", "gzip, deflate, br")
.WithHeader("Accept-Language", "en-US,en;q=0.9")
.WithHeader("Cookie", """YOUR_COOKIES_HERE - copy them from the browser""")
.GetStringAsync();
var matches = Regex.Match(response, "class='readingTimeline__text'>\n(.+)(\n.+){2}\nStarted Reading");
string timeStr = "";
DateTime date;
bool suc = true;
try
{
timeStr = matches.Groups[1].Value;
suc = DateTime.TryParse(timeStr, out date);
var book = new GrBookDateData { BookId = bookId, rawHtml = response, readDateString = timeStr, readDate = date, hasError = !suc, errorMsg = suc ? "" : "Invalid date format" };
dates.Upsert(book);
}
catch (Exception ex)
{
var book = new GrBookDateData { BookId = bookId, rawHtml = response, readDateString = timeStr, hasError = true, errorMsg = ex.Message};
dates.Upsert(book);
}
await Task.Delay(new Random().Next(1202, 2938));
}
}
// You can define other methods, fields, classes and namespaces here
class GrBookDateData
{
[BsonId]
public string BookId { get; set; }
public string readDateString { get; set; }
public string startedDateString { get; set; }
public string rawHtml { get; set; }
public DateTime? readDate { get; set; }
public DateTime? startedDate { get; set; }
public DateTime created {get;set;} = DateTime.Now;
public bool hasError { get; set; }
public string errorMsg { get; set; }
}.Dump() method.Everything else remains the same. Best of luck.



Comments ()