Elemental words
“When I heard oxygen and magnesium hooked up, I was like OMg.”
This joke more or less started it. We started exchanging similar ones with a friend and soon after I found myself wondering what fraction of the vocabulary is it possible to write using only the symbols of chemical elements. The thought nagged me until I gave in and started coding.
Basically I was trying to convert as many words as possible into an alphabet consisting of these “letters”:

So for example stab becomes STaB. There of course are many words where such transcription isn’t possible, and some where there are multiple possibilities, like chewiness, which becomes CHeWInEsS, CHeWINEsS, or CHeWINeSS.
So my goal was to find all the possible transcriptions for as many words as possible and look at some stats.
Results
The English dictionary I used (see below) contained about 62,077 words. All the common ones were there. As for the long ones, there was for example antidisestablishmentarianism, but no floccinaucinihilipilification.
In the end, I have been able to convert 10,857 words, which is a nice ~17.5%. The longest convertible words were nonrepresentational and underrepresentation with nineteen characters each. The word innocuousness had the most variations: twenty four.
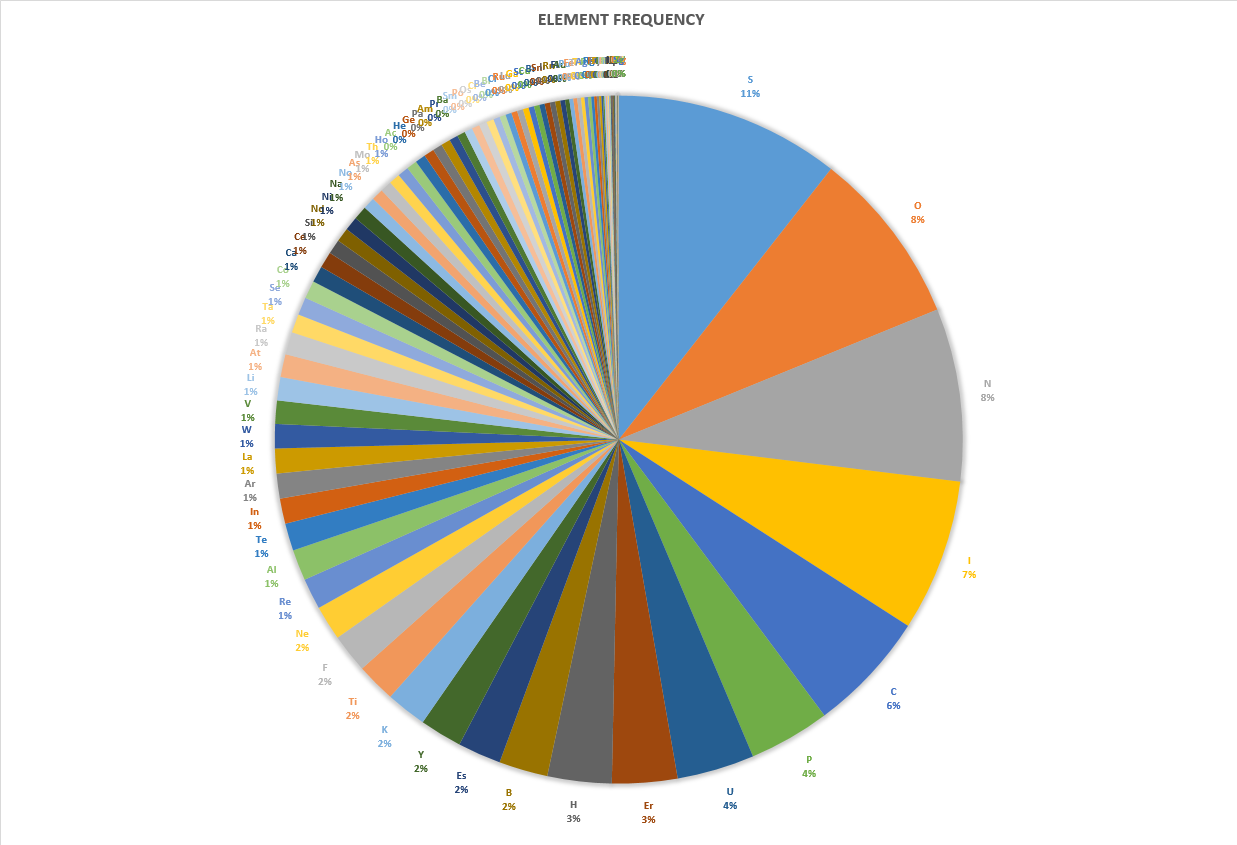
This chart shows how often a certain element was used. Not surprisingly, the single-lettered ones are on top, while the three-lettered ones were never used. (And notice how it spells "Sonic Pu-Erh". That’s certainly very important.)
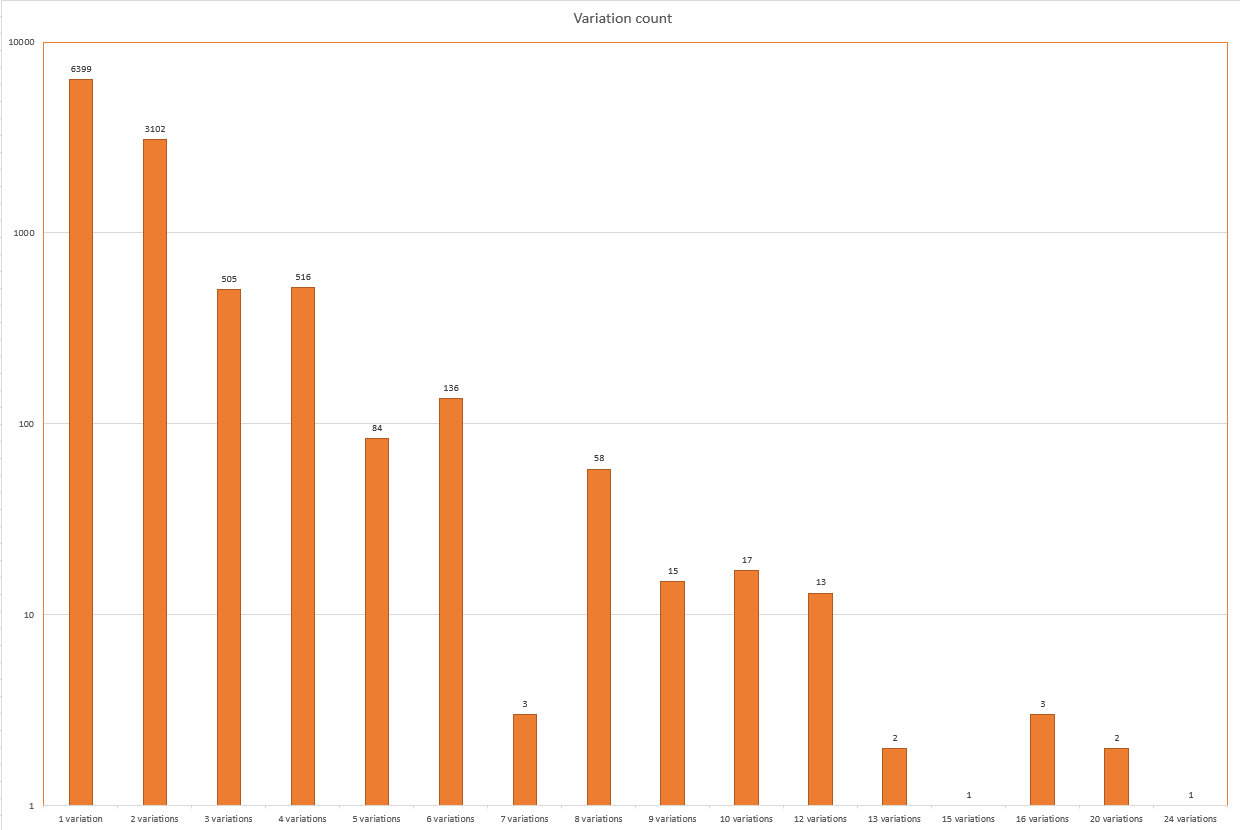
This is a histogram of variations. Notice the y-axis is on a logarithmic scale, i.e. the difference is 10 between the bottommost two lines and 9,000 between the topmost two. It shows that there were 6,399 words which had exactly one possible transcription, 3,102 with two, 505 with three and so on. An attentive reader probably already noticed the exponential trend in both of these charts.
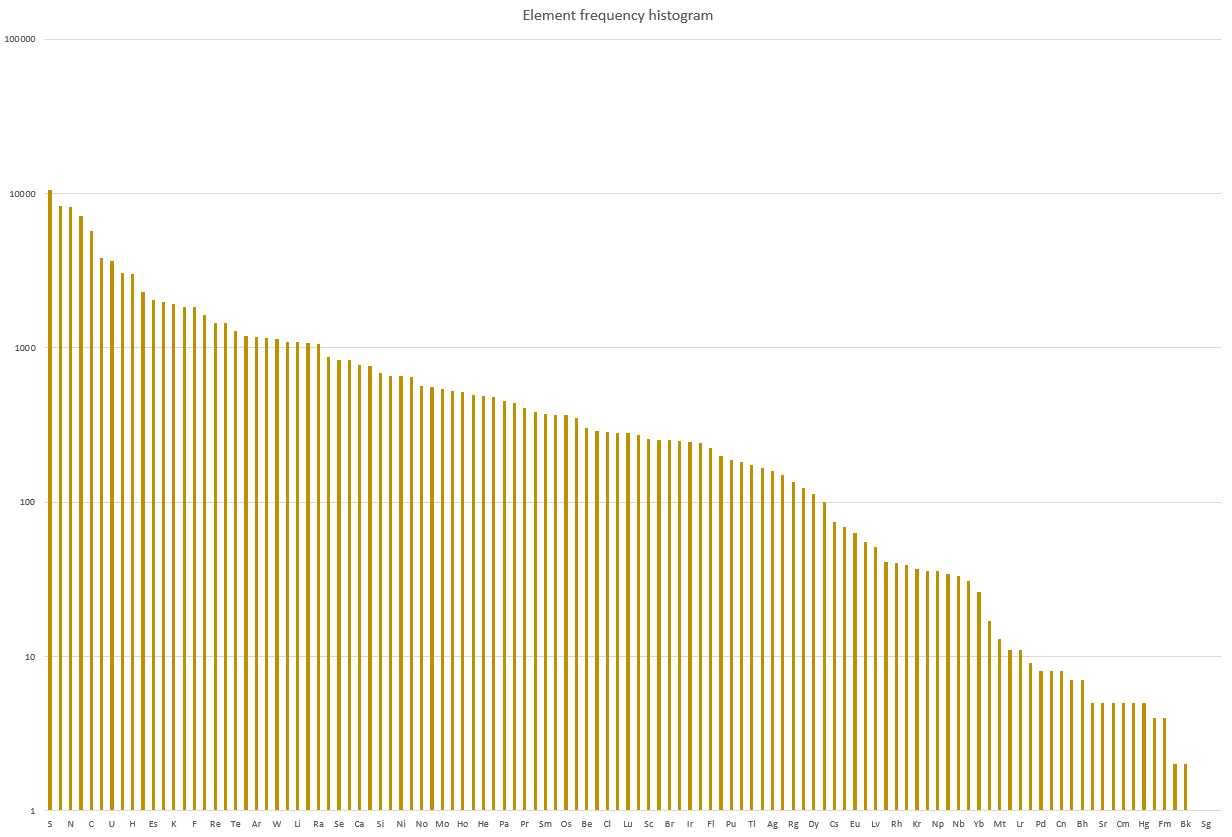
That means there are a couple of elements with very many uses, and very many elements with only a couple uses.
Only now did it occur to me to actually try putting floccinaucinihilipilification in. And it worked. It isn’t reflected in the charts above, but it is the only word that has eighteen variations and became the longest of the convertible words.
Other languages
I did this for two other input sets. Slovak, because it’s my native language, and the vocabulary used in the song Dovahkiin in the dragon language, because… actually I no longer remember why, but it probably had had something to do with Peter Hollens’ rendition of Skyrim’s theme.
The results for Slovak were as follows:
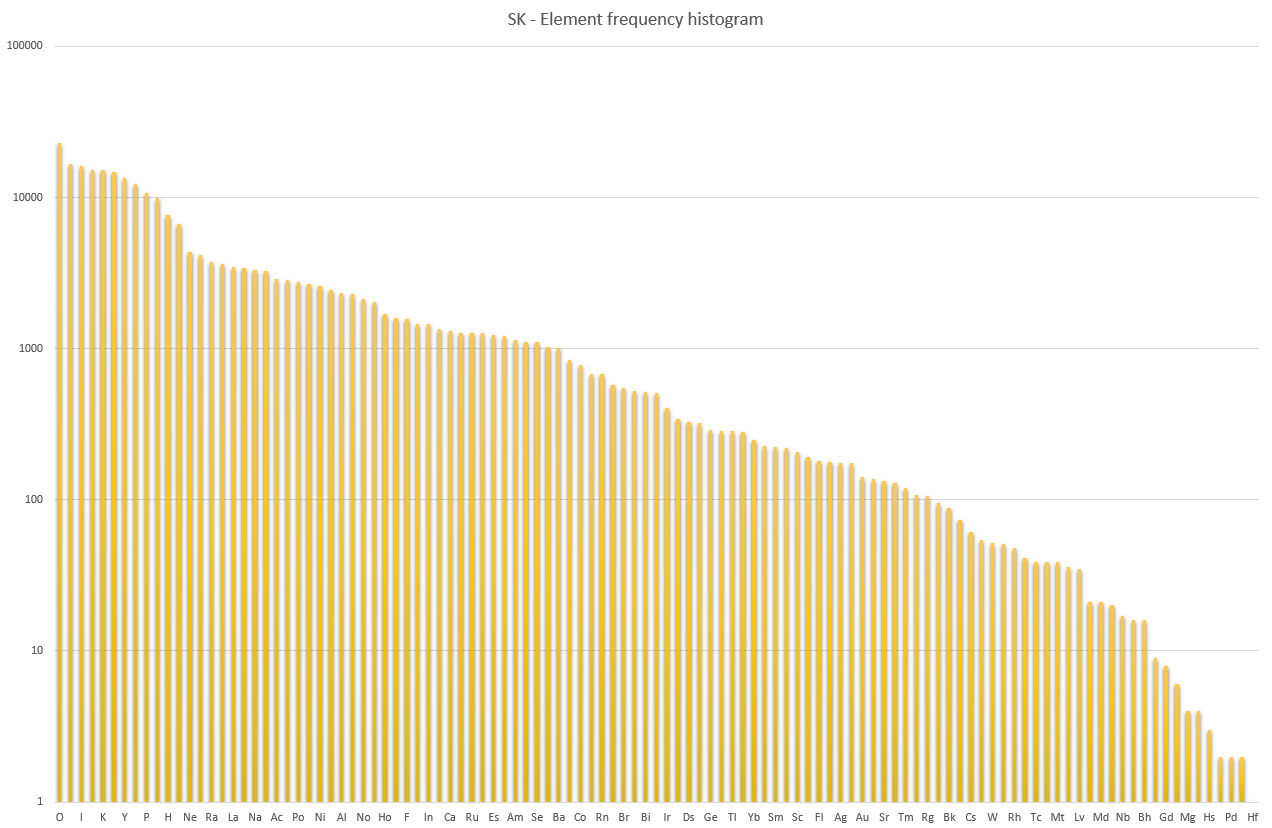
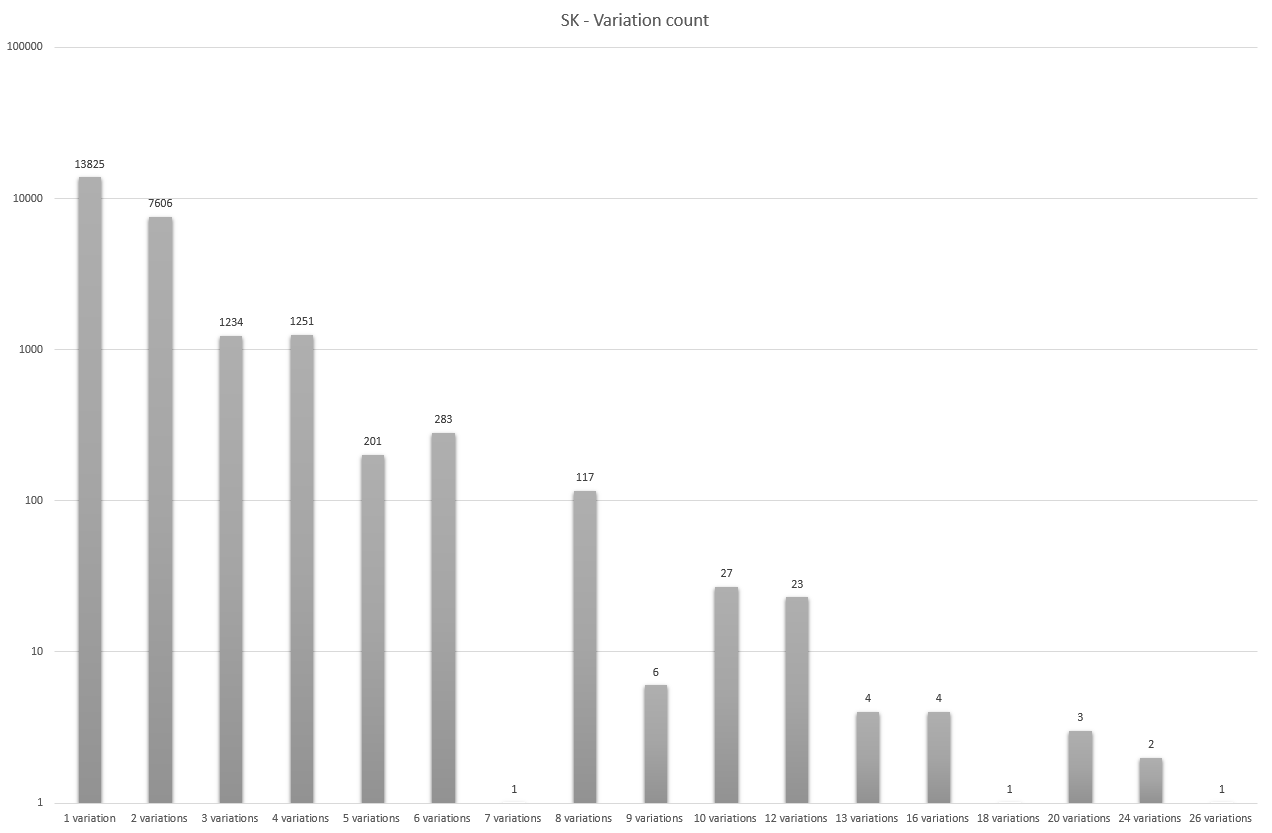
The longest words were balneoterapeutických, internacionalisticky, internacionalistický, and psychoterapeutických. Neúnosnosti had the most variations; twenty six.
And as for the dragon language:
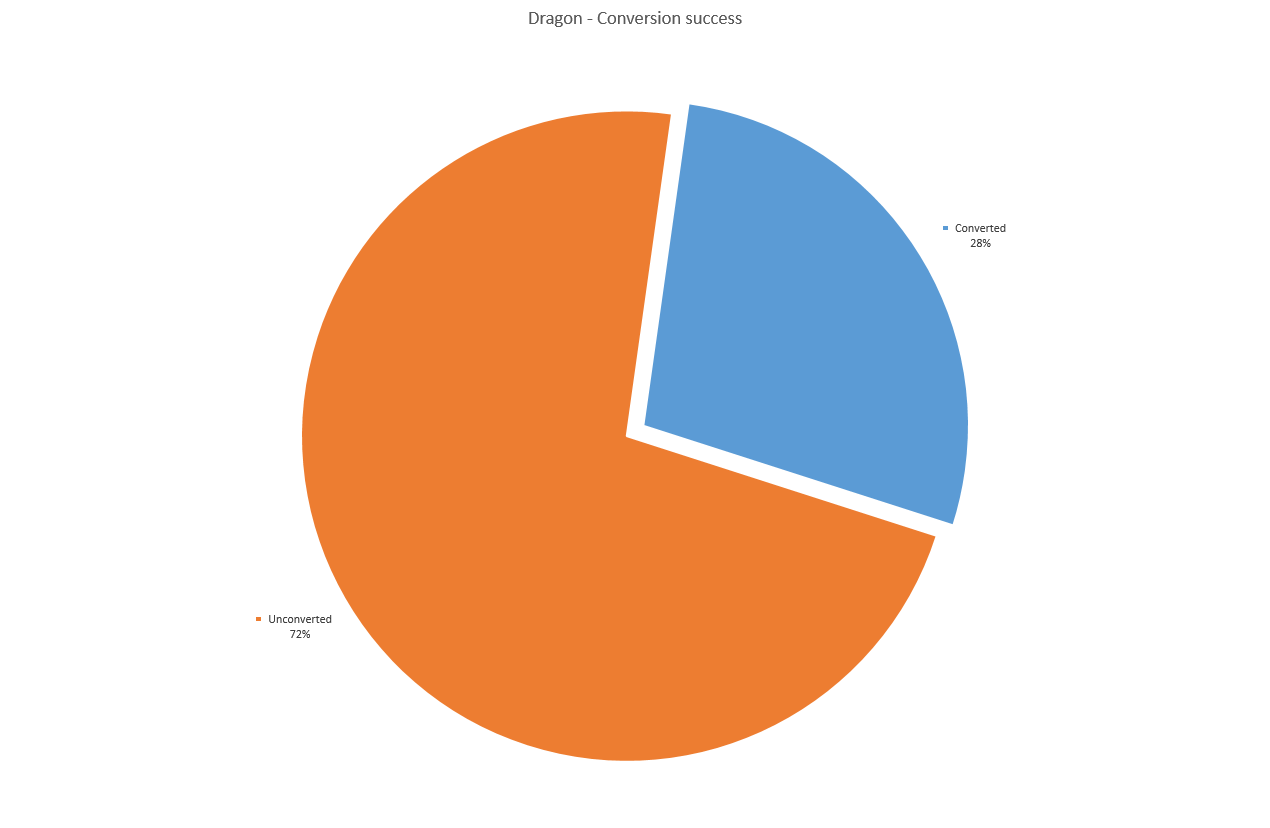
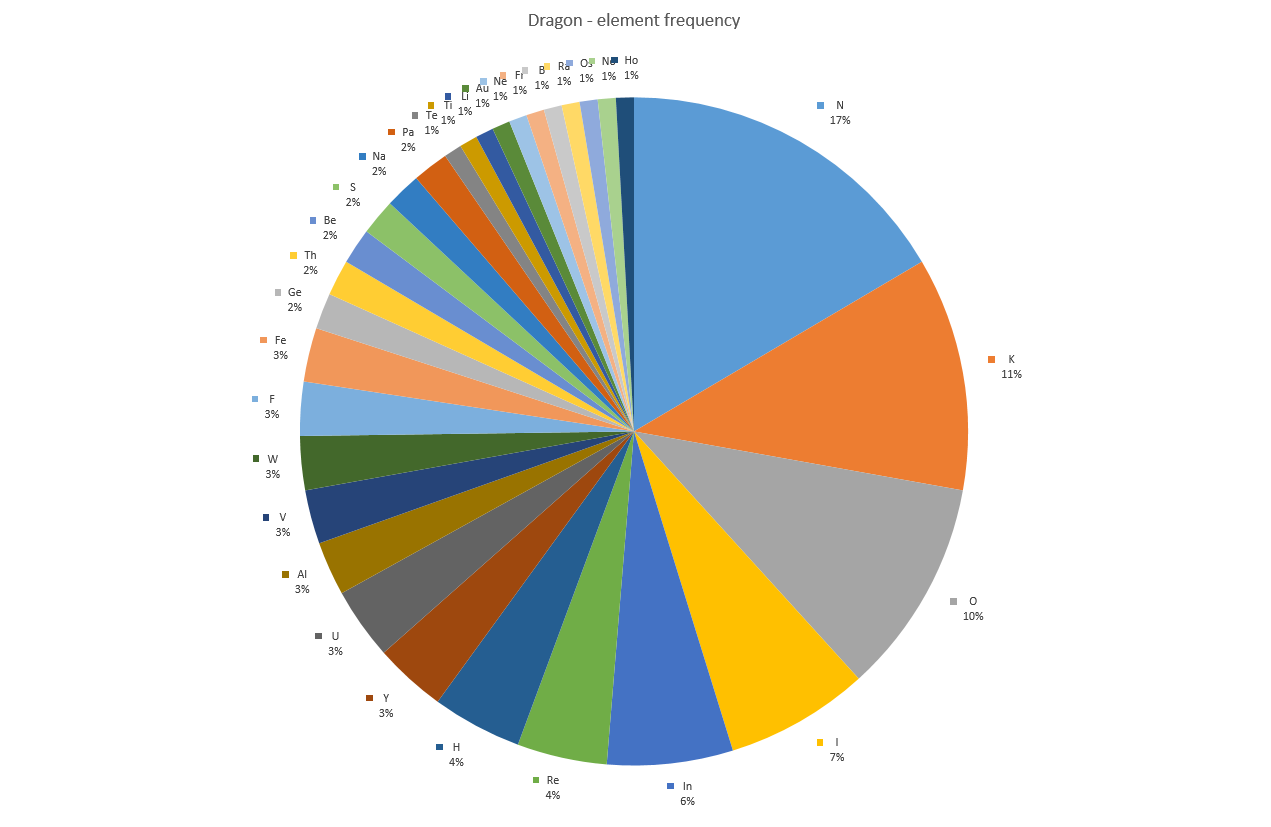
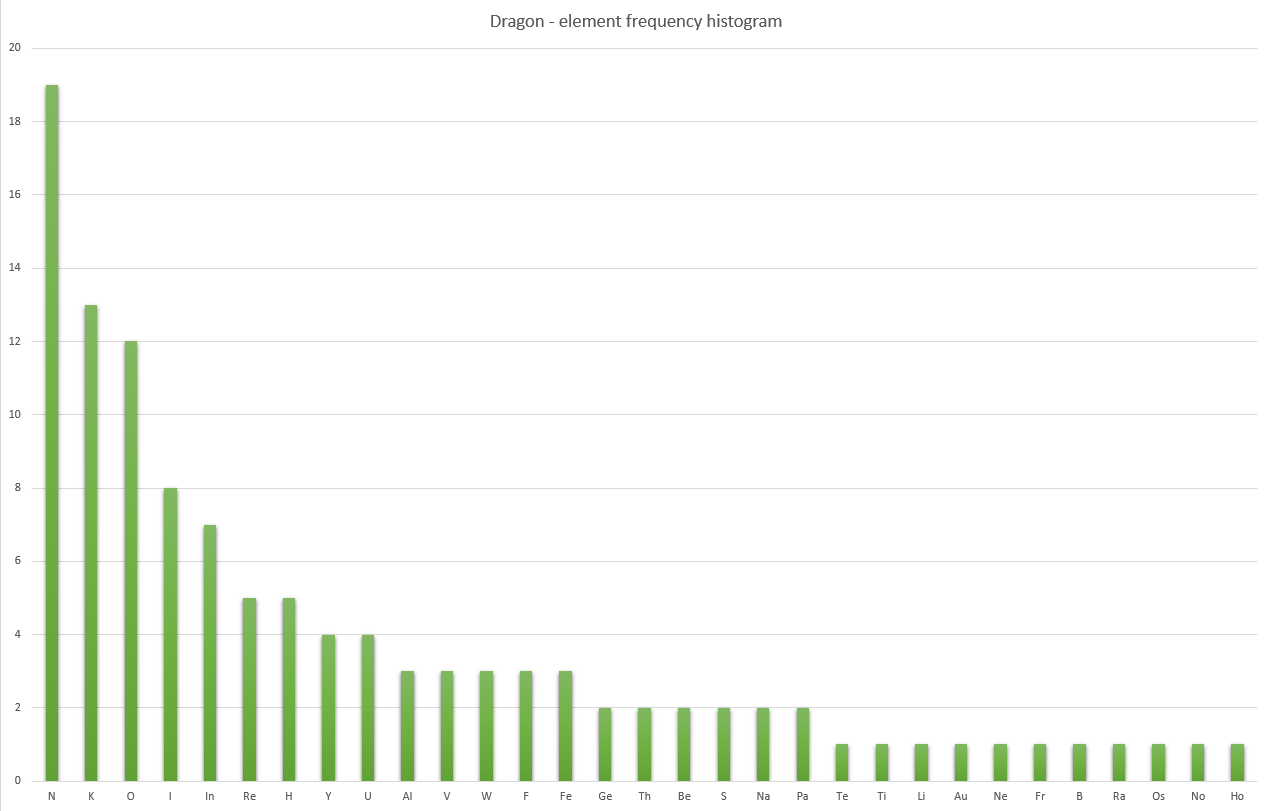
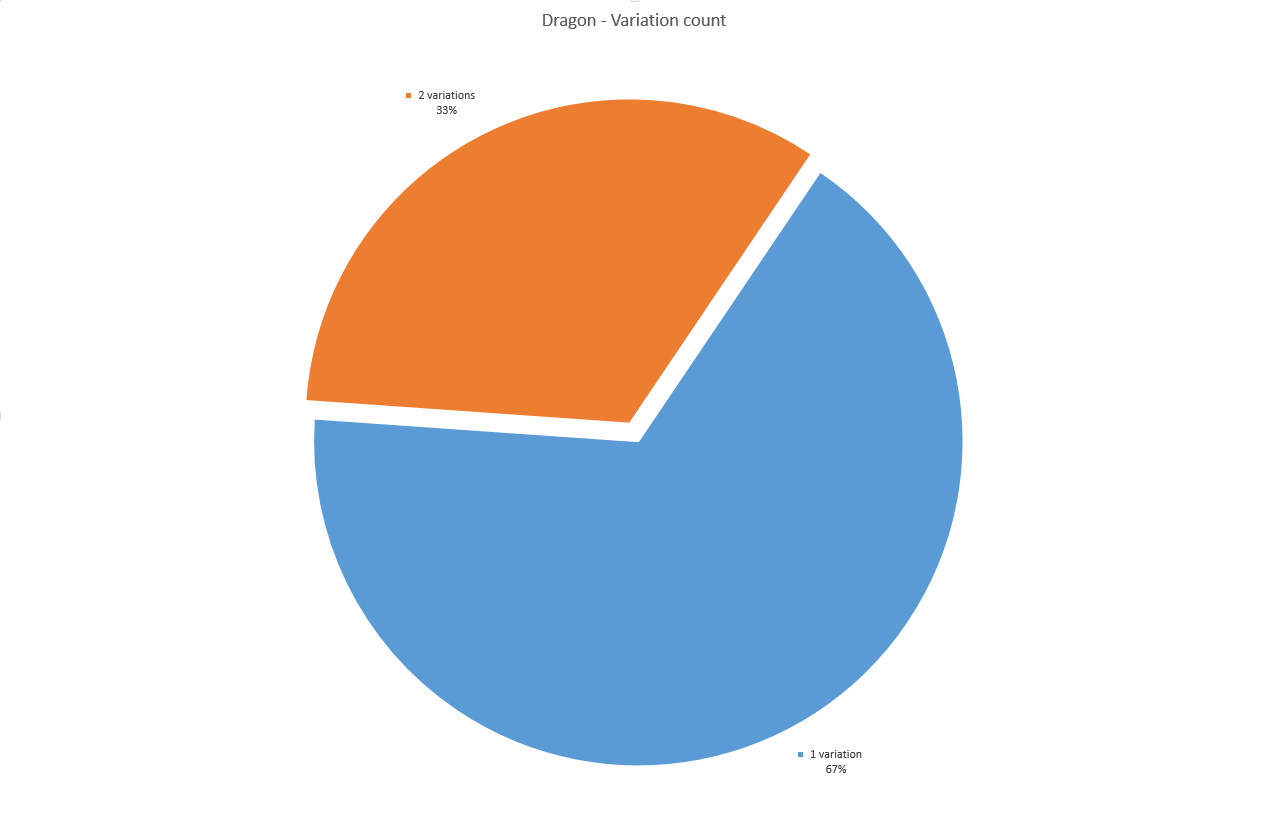
33 out of 119 words were convertible. The longest is being reyliik. There were eleven words with a maximum of two variations, as the words were mostly short.
Implementation
Warning: the code ahead is not exactly pretty. I didn’t care much for style. A simple explanation of its workings is provided. Everything is written in scriptcs. (In case you don’t know it, scriptcs is an awesome scripting language – C# with NuGet and all the good stuff. Check it out.)
Input data
While I wanted to cover as many words as possible, I didn’t really care about getting them all, missing or skipping some, etc. In the end, I ended up using OpenOffice’s dictionaries. This one for English, containing about 62,000 words, and this one for Slovak, with about 182,000. I don’t know why the EN is that much smaller and I didn’t bother with finding out. Maybe it’s because the SK version also contains many inflected word forms?
They both contained grammar info after a slash, and the SK one naturally has many accented letters. All of those have to be stripped. (So e.g. line pôvodkyňa/U becomes povodkyna). The first part is done here:
using System.Globalization;
using (var stream = new StreamReader("en_US.dic"))
using (var output = new StreamWriter("output_file_name"))
{
while (!stream.EndOfStream)
{
var word = stream.ReadLine().Trim();
var slashPos = word.IndexOf('/');
if (slashPos > 0)
{
word = word.Substring(0, slashPos);
}
output.WriteLine(word.ToString(CultureInfo.InvariantCulture));
}
}
This results in a nice file, suitable for manual browsing or further processing.
Code
The implementation is recursive and really simple. For each word, check whether it starts with a known element symbol. If it doesn’t, stop – this word can’t be transliterated. If it does, mark the symbol used and repeat the process with the rest of the word. If the beginning matches multiple symbols, try all of them.
A quick illustration: let’s start with snowbank. It starts with S, so we write it down and continue wit the rest. nowbank starts with No, so now we have S No and continue with wbank. Or we could continue with N instead of No, getting S N and continuing with owbank. (Since we want to find all the possibilities, we branch and do both.) After doing this exhaustively, end up with SNoWBaNK, SnOWBaNK, SNOWBaNK.
The script also gathers some statistics used above and churns everything out into the standard output.
If you wanted to try it for yourself, everything is available on GitHub. The code is only a couple tens of lines long.

Comments ()