Universal Personal Search - the tech stack
The previous post on building a Search app that would index all of my data outlined what I want to achieve, but didn't go into any technical details. This post briefly outlines those.
There are 3 main parts: The most important thing here is, unsurprisingly, the search engine. Every data source will first have to provide data to the engine, which will create indices as needed, then facilitate the search. Last but not least, there needs to be a UI for searching.
While the entire thing works now, I treat it as a beta version - there are still plenty of data sources missing, and the UI needs work as well.
Picking the search engine
Just like everyone else, I've also heard of ElasticSearch. I gave it a try, but didn't like it much right from the get-go: it was a total overkill. And no wonder - it's built primarily for heavy-duty use cases. But for me, running 4-5 docker containers just to run a search engine that will service tens of queries per day isn't great. It would be more difficult to maintain and program.
Then I fortuitously stumbled upon MeiliSearch.
It seemed to have all the features I'd like and more. And it was easy to deploy and use!
There's just a single Docker container to get up and running. I can send a simple post request with a JSON payload to load data into it. Another JSON post can set up configuration for each index: which fields should serve as facets, which are sortable, etc. I can define synonyms, there's typo resiliency and much more.
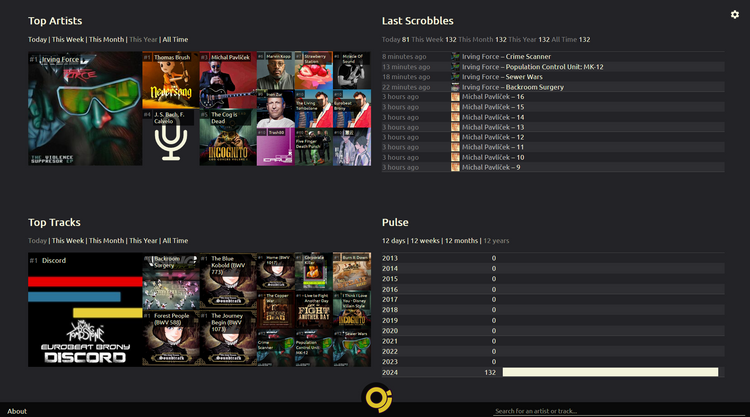
What was even better: when I ran it in "development" mode, I got a simple search UI out of the box.
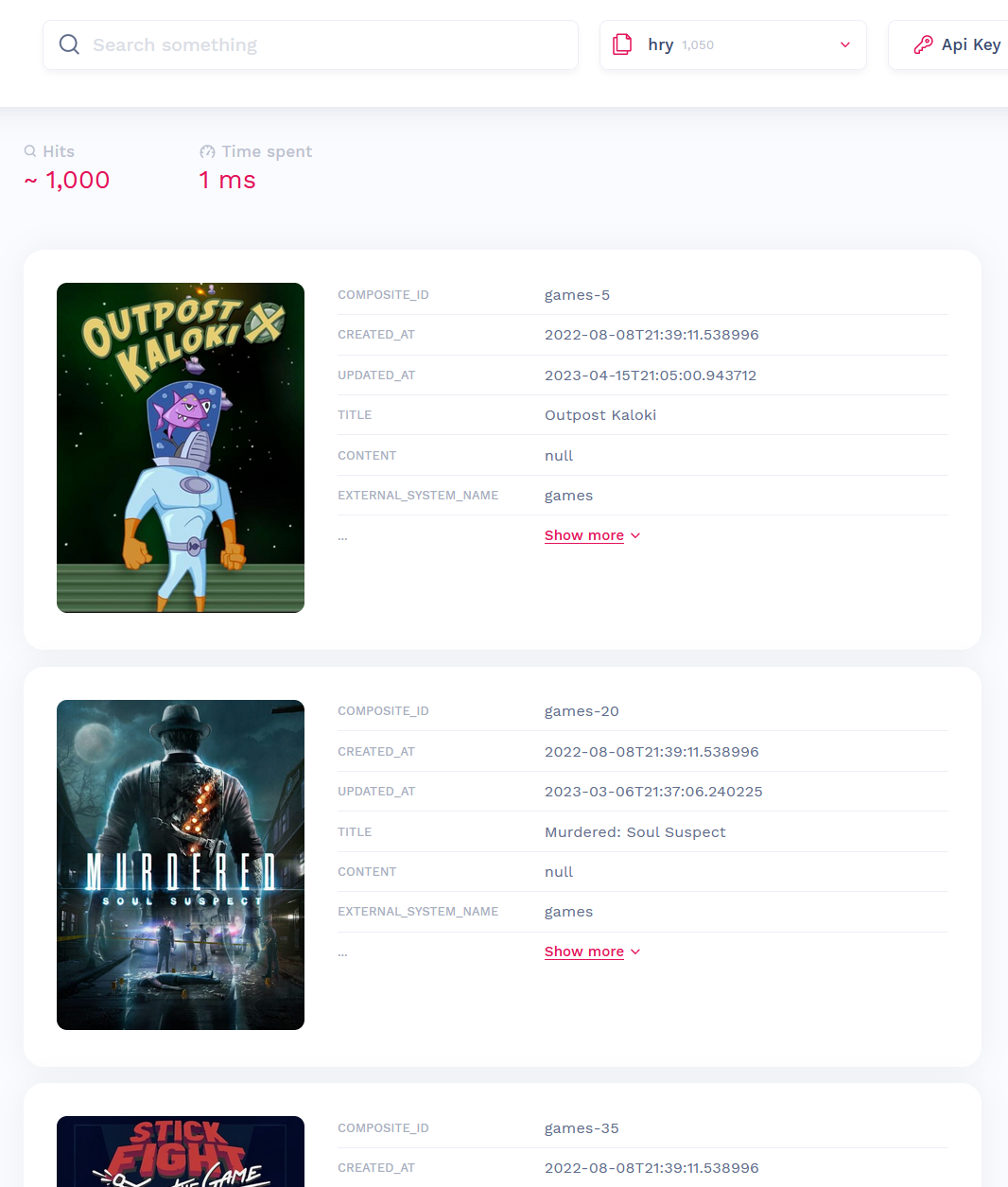
It could only do the basics - search only one index at a time, search all fields, and the output is just a table of the entire JSON document. (But look, it even handles pictures! I'm impressed.) But even then it was very useful: I could spin up a local container, try various things, load data, and so on.
When I had the basics done, I ran a container on my production server - still in dev mode. It wasn't exposed to the net, and was only reachable via my Tailscale VPN. This turned out to be immensely useful: I could actually use my search at least in some capacity weeks before I had enough time to make an actual front-end for it.
Data sources
The easiest candidate was also the most needed one: my data in NocoDB. That's an open-source alternative to (my use cases for) AirTable. I could just work on the Postgres DB it runs on: so I've created DB views that returned a single line with the entire JSON payload to be loaded into Meili. (The more I use Postgres, the more I like it.)
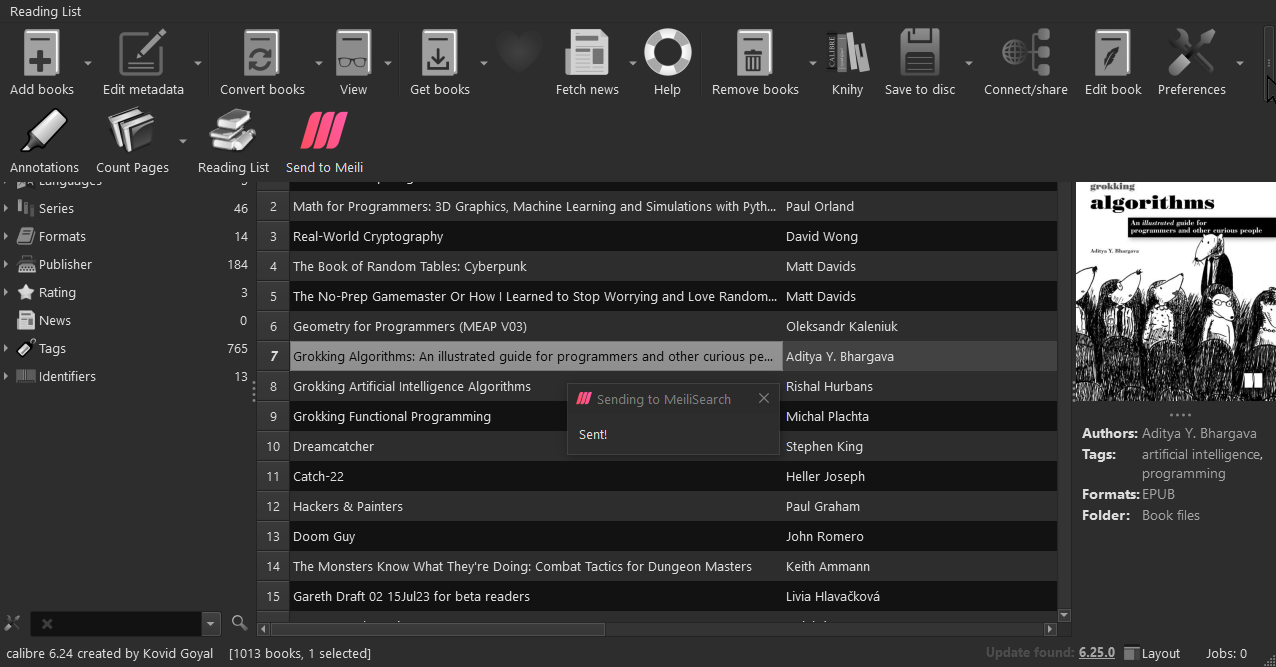
Then I wired up a simple n8n workflow that periodically downloads the data from the views, and sends them to Meili.
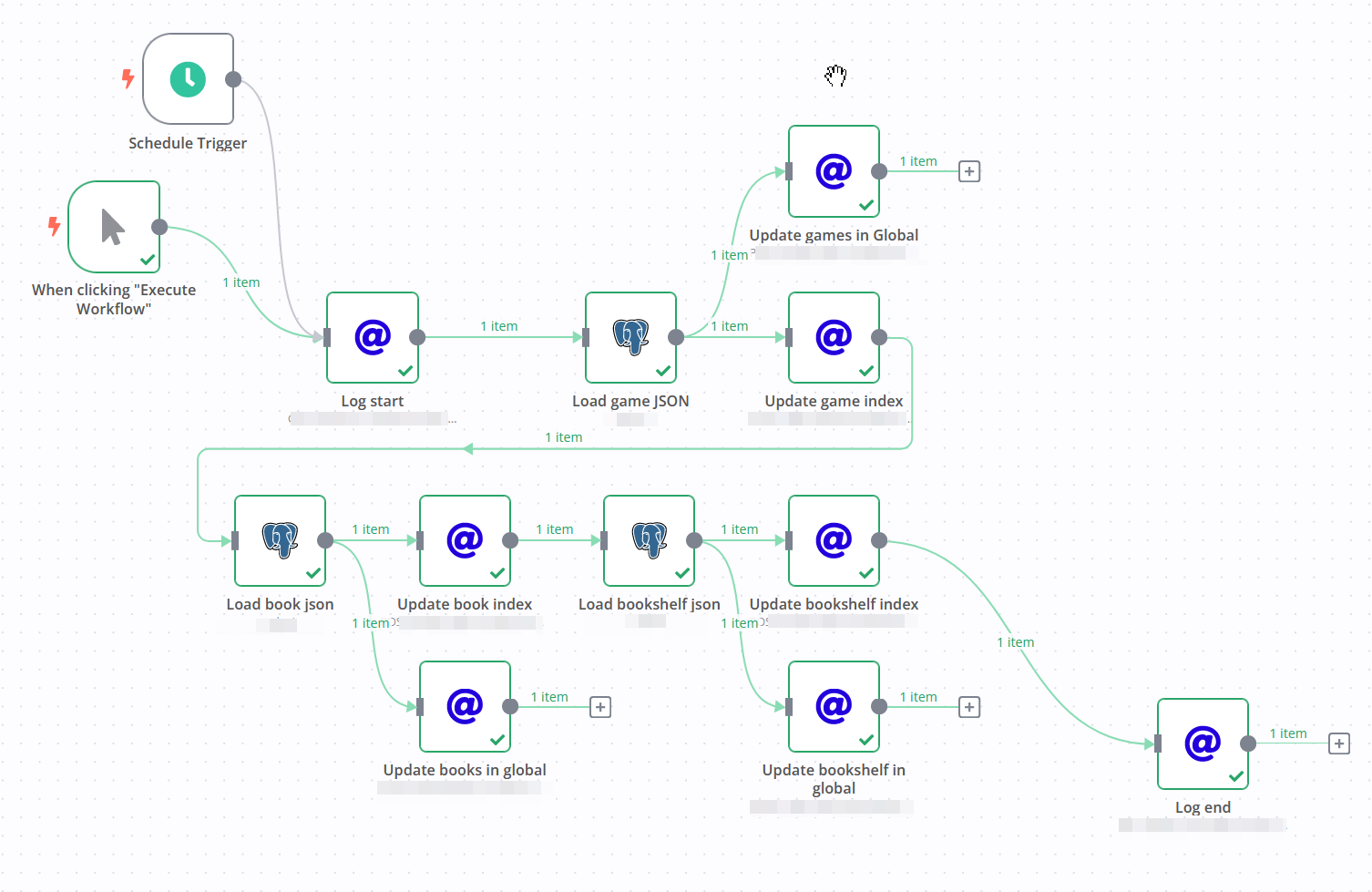
I didn't over-complicate it: every time, I just extract the entire table and send it; Meilisearch handles the updates. The entire thing takes seconds.
You can see in that screen that I'm sending everything twice: I've decided for UI-related reasons (more on that below) to load every data source into its own index, as well as a single 'global' index that will contain everything.
That works because of the:
Common data structure
Since I want all the results on a single screen, it makes sense to have some common elements in all of the index entries.
Every entry needs to have a:
- Title
- Description
- Name of the data source it came from
- Related to that, a type ("bookmark", "note", ...)
- ID in the external data source
- Creation and Modification timestamps
- A list of tags
- A cover image URL
- An external URL ('this record is related to this link')
- An internal URL (the permalink for this record in my personal stack)
- A 'favorite' flag
Any record can have additional fields for data - a book might have an Author, a Purchase date, or a Read date, for instance. However, since these are common, they can serve as facets or sortable fields in the global index.
UI
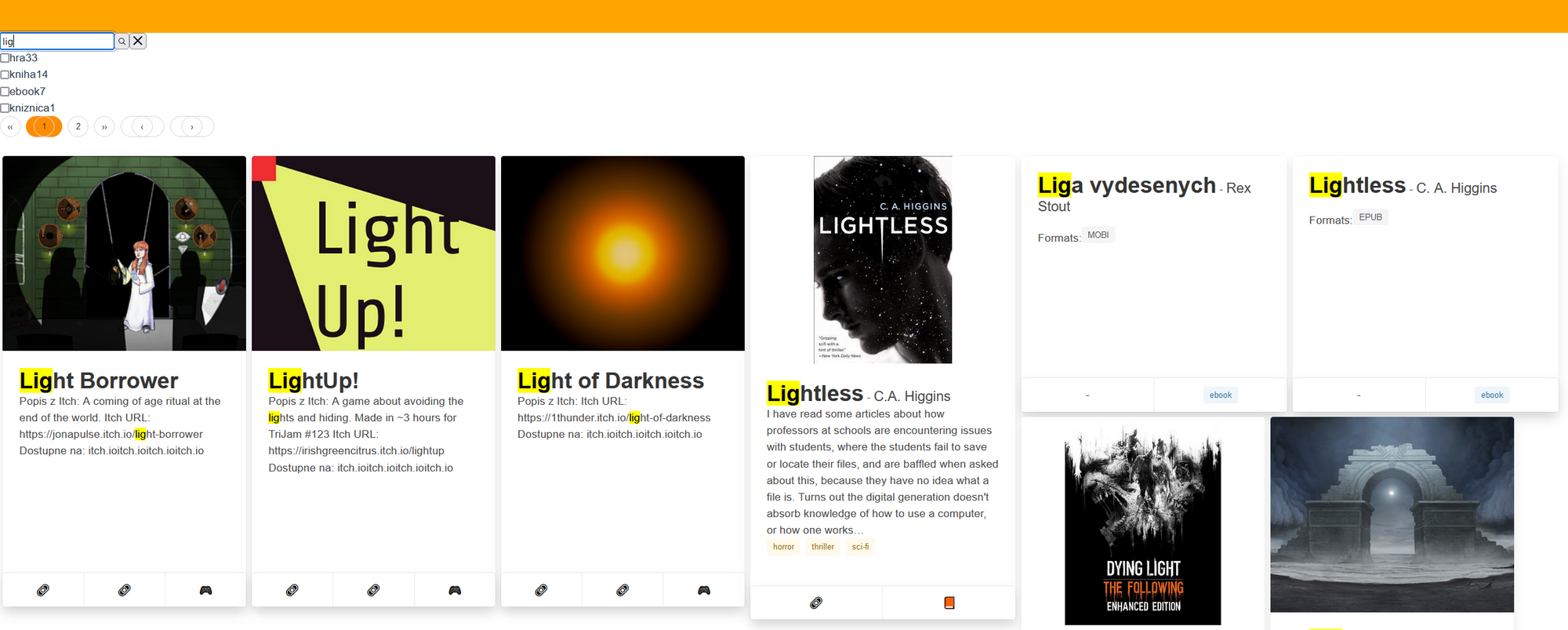
With the search engine and data sources in place, the last piece of the puzzle was a UI. The previous post had a video of it in action, but it looks like this:
I have experience with Vue (e.g. on Obskunee) and kinda like using it. And Meilisearch is ready: they provide components for Vue, which depend on Algolia's InstantSearch for Vue components. I had to learn those, but it wasn't too hard.
I originally intended to only have a single index for each data source, and use Meili's "Multi Index Search" feature. While that is possible, the Vue library components render the search results in separate lists per each index. I've experimented with that a bit, but didn't like it too much: I want all of the things to be mixed together. That's why I created the single, global index with all entries.
Result cards
The search results (pictured above) have a card for each hit. Since there's a shared data structure for each data source, it was easy to build a generic "search result card" - it shows the image, title, description, and tags. In the footer, it shows the internal and external links, and "type".
When I have free time, this also makes it easy to add specialized cards: for instance, I've added a card for "read books". It shows book-specific attributes, such as author, or date read. Every specialized card also indicates its type with an icon instead of text - this makes the results more glanceable.
Final thoughts
I like the tech stack I ended up with. It's surprisingly pleasant to work with, and pleasant to use.
There's a lot more work to be done:
- Obviously, the design could use a lot of work, but it's the least important part and will have to wait.
- Better facets and sorting: For now, the only filterable facet is the Type.
- More data sources: notes, blogs, public link feed (links.zblesk.net), private web archive, etc. This is the most important one: no data means a sucky search.
- Per-index search tabs: I could have specialized search tabs that only search a single index (say, books) instead of the "global" one. That would let me use more specific facets and sorts.

Comments ()